大数据(二)大数据架构发展史
1.背景
随着数据量的暴增和数据实时性要求越来越高,以及大数据技术的发展驱动企业不断升级迭代,传统数仓经历了以下发展过程:传统数仓架构 -> 离线大数据架构 -> Lambda架构 -> Kappa架构 -> 新一代实时数仓。(大部分网上文章最后一个时代竟然写的是混合架构,笔者非常不赞同,因为加了机器学习、IOTA架构加了物联网边缘计算的概念。这两者建议单独出来写架构。属于特殊业务场景的架构。相反,笔者认为这里有必要新增一个“新一代实时数仓架构”,这种架构才是和前几个架构一个级别的)具体如下图:

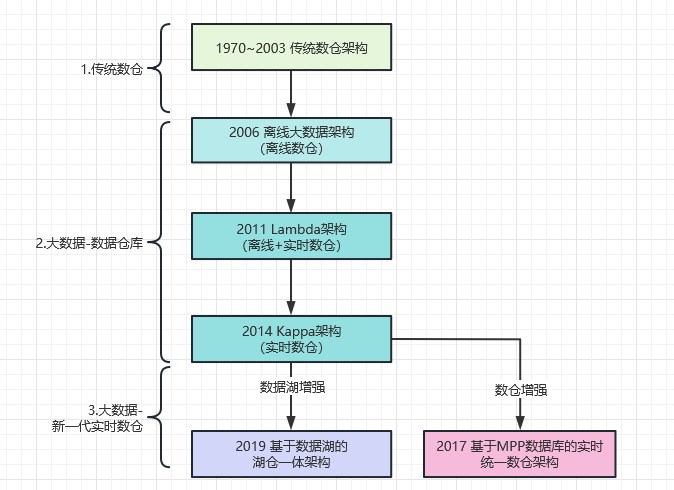
仔细看上图,主要包含3大发展阶段:
- 1970~2003 传统数仓阶段
- 2003~2016 大数据-数据仓库阶段
- 2016~至今 大数据-新一代实时数仓阶段
下面我们拆成2大块来讲解,一块是传统数仓,一块是大数据(数据仓库+新一代实时数仓)。看看过去几十年,大数据经历了什么变迁。
2.传统数仓发展史
传统数据仓库的发展史,由于已经成为历史,就不展开技术栈细讲,只需快速过一遍即可。了解这个历史发展过程即可。
2.1 传统数仓理论史
2.1.1 5个时代
传统数仓发展史可以称为5个时代的经典论证战。按照两位数据仓库大师 Ralph kilmball、Bill Innmon 在数据仓库建设理念上碰撞阶段来作为小的分界线:
-
1970~1991 数据仓库概念萌芽到全企业集成。
-
1991~1994 EDW企业数据集成时代。Bill Innmon 博士出版了《如何构建数据仓库》,范式建模。
-
1994~1996 数据集市时代。 Ralph Kimball 博士出版了《数据仓库工具箱》,里面非常清晰的定义了数据集市、维度建模。
-
1996~1997 神仙大战时代(维度建模与范式建模争论)
-
1998~2001 合并时代,CIF架构。Bill Innmon推出了新的BI架构CIF(Corporation information factory),把Kimball的数据集市也包容进来了,第一次,Kimball承认了Inmon。
2.1.2 经典争论
如果说,Hans Peter Luhn和Howard Dresner,一个为了文本挖掘,一个为了企业管理中的信息民主,而定义了BI(智能商业)的话。那么Bill Inmon 和Ralph Kimball,这2位大师则通过不同理念,设计技术和实施策略使BI从定义落地为真实。两位大师在1991-2001,引领了传统数仓发展的一个时代。

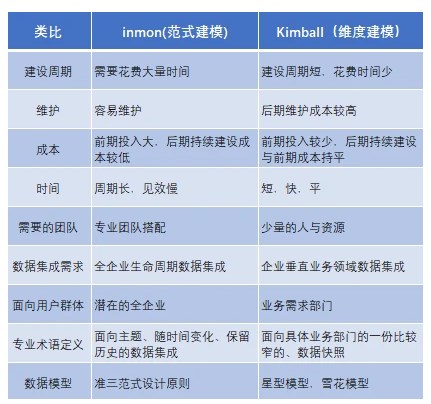
Bill Innmon和Ralph kilmball论证的核心在于EDW(企业级数据仓库)和数据集市的建立先后顺序(也可以理解为范式建模和维度建模的争论)。
- Bill Inmon 提出自上而下的建设原则(EDW->DM):提倡先数据模型创建企业级数据仓库EDW(3NF范式建模)后,再建数据集市(DM)。
- Ralph kilmball 提出自下而上的建设原则(DM->EDW):提倡先创建数据集市,认为数据仓库是数据集市的集合,信息总是被存储在多维模型(维度建模)中。后期可根据需要来合并数据集市,并逐步形成企业级的数据仓库(EDW)。
两种方法的明细区别如下表(摘自网络):

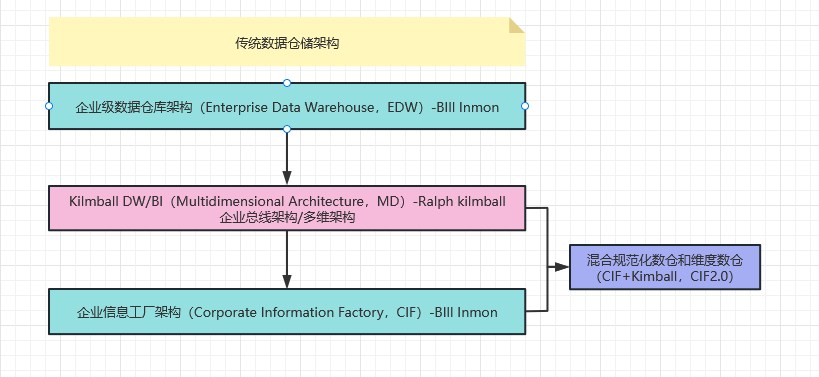
2.2 传统数据仓库架构史
伴随着kilmball和Innmon的经典争论,诞生了三代典型数据仓库架构(网上有些文章把Opdm操作型数据集市架构定义为第四代数据仓库架构,笔者不认可这一架构能和另外3个并列,故删之),分别是:
- 企业级数据仓库架构(Enterprise Data Warehouse,EDW)-BIll Inmon
- Kilmball DW/BI(Multidimensional Architecture,MD)-Ralph kilmball
- 企业信息工厂架构(Corporate Information Factory,CIF)-BIll Inmon
如下图所示:

2.2.1 企业级数据仓库架构(Enterprise Data Warehouse,EDW)-BIll Inmon
90 年代 BIll Inmon 出版《如何构建数据仓库》一书体系化的与明确定义了如何构建数据仓库,这套方法在落地上形成了第一代数据仓库架构。书中定义:数据仓库(Data Warehouse) 是一个面向主题的(Subject Oriented) 、集成的( Integrate ) 、相对稳定的(Non -Volatile ) 、反映历史变化( Time Variant) 的数据集合,用于支持管理决策( Decision Marking Support)。具体如下图所示:

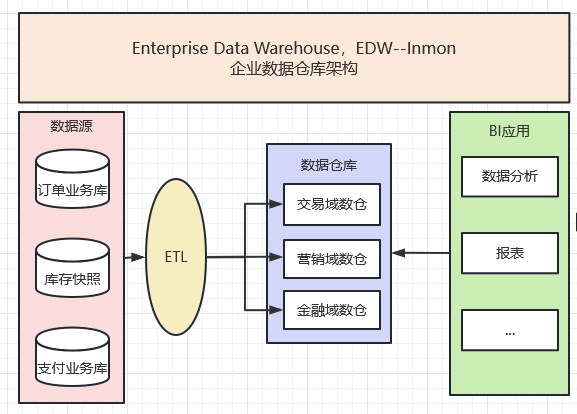
从左至右依次是数据源、数据清洗、数仓、应用。
核心原理:
- 数据仓库是面向主题的。
- 数据仓库是集成的,数据仓库的数据有来自于分散的操作型数据,将所需数据从原来的数据中抽取出来,进行加工与集成,统一与综合之后才能进入数据仓库。
- 数据仓库是不可更新的,数据仓库主要是为决策分析提供数据,所涉及的操作主要是数据的查询。
- 数据仓库是随时间而变化的,传统的关系数据库系统比较适合处理格式化的数据,能够较好的满足商业商务处理的需求,它在商业领域取得了巨大的成功
2.2.2 Kimball DW/BI架构(Multidimensional Architecture,MD)-Ralph kimball
第二代就是 Kimball DW/BI架构。又称Multidimensional Architecture(MD)多维架构,或Bus Architecture总线架构。即从业务或部门入手,设计面向业务或部门主题数据集市。(网上大部分都说Kimball的数据集市架构,笔者不赞同。Kimball提倡的是维度建模、总线架构思想。Kimball架构甚至都不包含物理的数据集市,而是逻辑概念上的)Kimball DW/BI架构从流程上看是是自底向上的,即从数据集市到数据仓库(DM->DW)的一种敏捷开发方法。这种构建方式可以不用考虑其它正在进行的数据类项目实施,只要快速满足当前部门的需求即可,这种实施的好处是阻力较小且路径很短。
核心原理:一致性维度建模(总线型架构)+ 基于企业总线的数据仓库
但是考虑到在实施中可能会存在多个并行的项目,是需要在数据标准化、模型阶段是需要进行维度归一化处理,需要有一套标准来定义公共维度,让不同的数据集市项目都遵守相同的标准,在后面的多个数据集市做合并时可以平滑处理。比如业务中相似的名词、不同系统的枚举值、相似的业务规则都需要做统一命名,这里在现在的中台就是全域统一ID之类的东西。具体如下图所示:

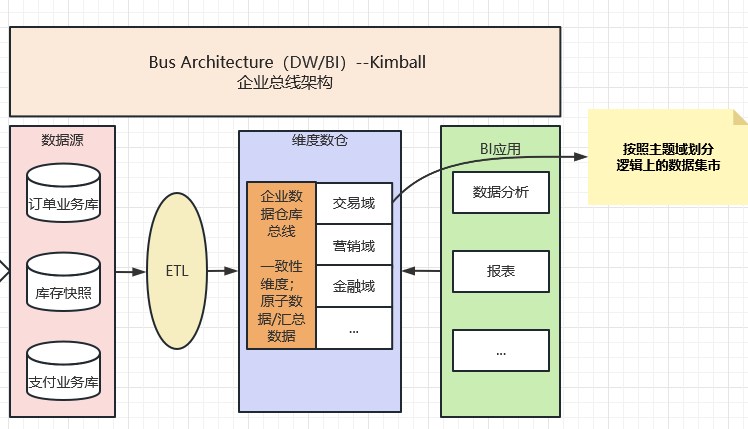
注意:kimball架构的数据仓库是没有实际存在数据集市的,如果非要区分,可以通过主题域划分获取自己的数据集市。(比如上图的维度数仓下的交易域数仓,可以理解为逻辑上的数据集市。预留数据集市飞机票//TODO)
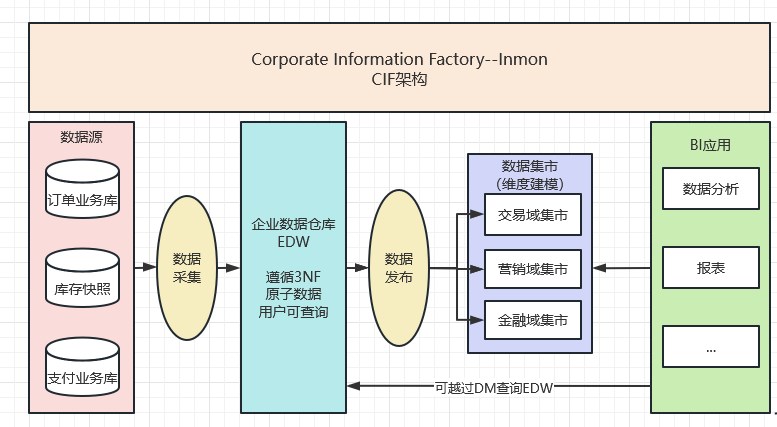
2.2.3 企业信息工厂架构(Corporate Information Factory,CIF)-BIll Inmon
第三代架构就是CIF架构,CIF强制引入了一层规范化的、原子的(满足第三范式)企业数据仓库EDW。这一层承担了数据协调和集成的职责。Inmon 模式从流程上看是自顶向下的,即从数据仓库再到数据集市的(DW->DM)。
核心原理:Inmon EDW企业数仓(遵循3NF)+ 数据集市。具体如下图所示:

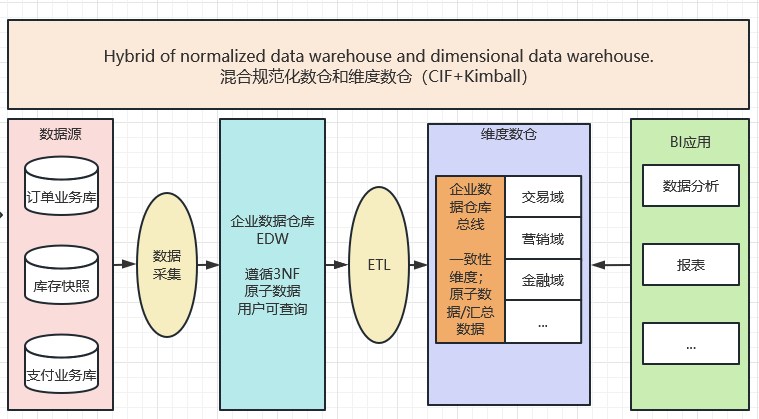
混合架构(CIF+Kimball,CIF2.0)
混合架构是CIF架构的变种,可以认为是CIF2.0架构。BIll Inmon把Kimball的多维架构融入进来(据说Inmon很生气,没能说服Kimball,一气之下把Kimball架构也融进去了…)。并限定EDW不对外提供查询能力,其中的数据是维度的、原子的、以过程为中心的。这种架构主要适用于前期已经购入建设了原子级的EDW,但尚无法满足用户的灵活的分析需求,在这种情况下可以采用这种架构,算是一种无奈之举。 缺点很明显,EDW和维度数仓数据冗余造成资源浪费,架构复杂导致人力成本较高。
核心原理:Inmon EDW企业数仓(遵循3NF)+ Kimball 维度数仓(一致性维度)

3. 大数据架构发展史
2003年之后,随着企业数据量暴增和实时性需求增多,大数据技术开始蓬勃发展。到2006年,Hadoop诞生。Hadoop派系几乎主导了2006~2016这十年大数据发展史,大数据技术如雨后春笋般爆发式增长。但也带来了技术栈混乱、运维成本增加的问题。一直到2016年之后,新一代实时数仓诞生了。这个阶段强调:批流一体、湖仓一体的架构。有多种实现机制,其中最典型的2条路是:
- 1.数据湖增强数仓能力(湖仓一体 Lakehouse,支持批流一体式读写) :Flink + 开源数据湖【Iceberg、Hudi、Delta Lake】
- 2.数仓增强数据湖能力(新一代实时数据库支持批流一体式读写、支持联邦查询一站式OLAP解决方案):Flink+实时数仓【Doris、Clickhouse】


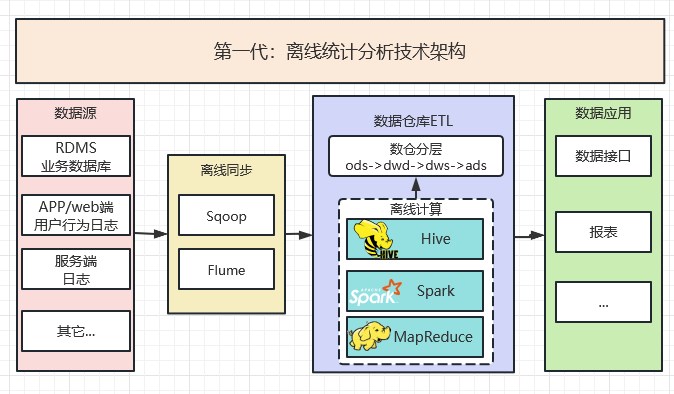
2.1 第一代:离线统计分析技术架构-2006
特点:
1、数据源通过离线的方式导入到离线数仓中;
2、数据处理(Hadoop、Spark技术派系为主):MapReduce、Hive、SparkSQL 等离线计算引擎。 架构及数据处理流程如下;

2.2 第二代:Lambda架构(离线+实时结合)–2011
随着大数据应用的发展,人们逐渐对系统的实时性提出了要求,为了计算一些实施指标,就在原来离线数仓的基础上增加了一个实时计算的链路,并对数据源做流式改造(即把数据发送到消息队列),实时计算去订阅消息队列,直接完成指标做增量的计算,推送到下游的数据服务中去,由数据服务层完成离线&实时结果的合并。Lambda架构如下图所示:


2.3 第三代:Kappa架构(批流一体)–2014
Lambda 架构虽然满足了实时的需求,但带来了更多的开发与运维工作,其架构背景是流处理引擎还不完善,流处理的结果只作为临时的、近似的值提供参考。 后来随着Flink等流处理引擎的出现,流处理技术很成熟了,这时为了解决两套代码的问题。 Linkedln 的 Jay Kreps 提出了 Kappa 架构,在实时计算中可以直接完成计算,也可以跟离线数仓一 样分层,取决于指标的复杂度,各层之间通过消息队列交互(多半是不分层的),Kappa 架构可以认为是 Lambda 架构的简化版(只要移除 Lambda 架构中的批处理部分即可)。Kappa 架构如下图所示:

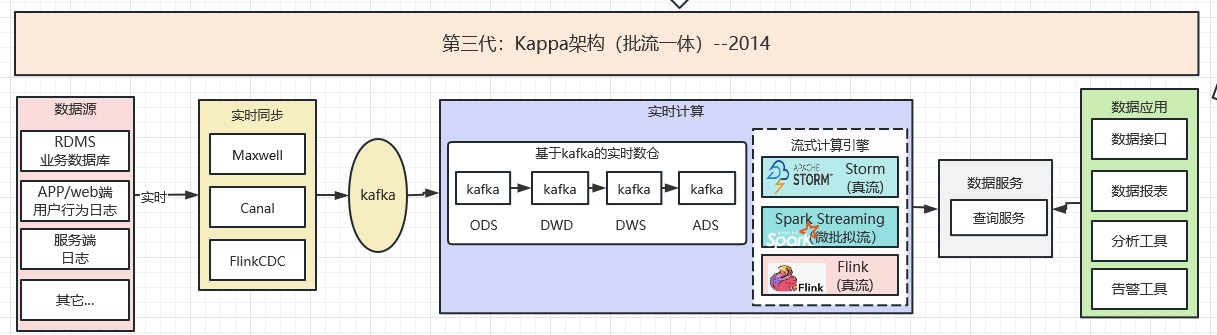
2.4 第四代:基于MPP数据库的实时统一数仓架构—数仓增强-2017
面对越来越强的OLAP数据分析需求,新一代高性能MPP数据库高速发展:2016年Clickhouse、2017年Doris相继面世。例如,Doris的实时数仓架构。其特点如下:
- 报表分析:面向用户或者客户的高并发报表分析(Customer Facing Analytics)。
- 即席查询(Ad-hoc Query):面向分析师的自助分析,查询模式不固定,要求较高的吞吐。
- 统一数仓构建 :一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。
- 数据湖联邦查询:通过外表的方式联邦分析位于 Hive、Iceberg、Hudi 中的数据,在避免数据拷贝的前提下,查询性能大幅提升。
具体如下图所示:

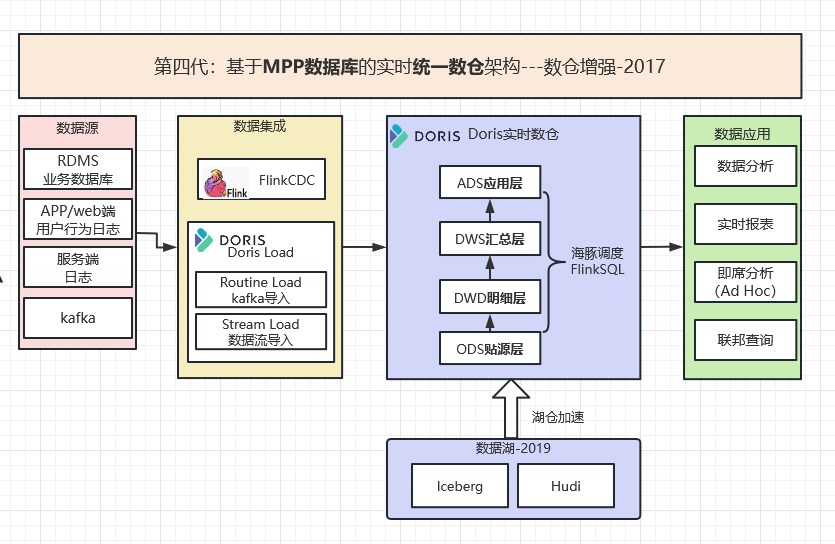
Doris官网应用架构图:

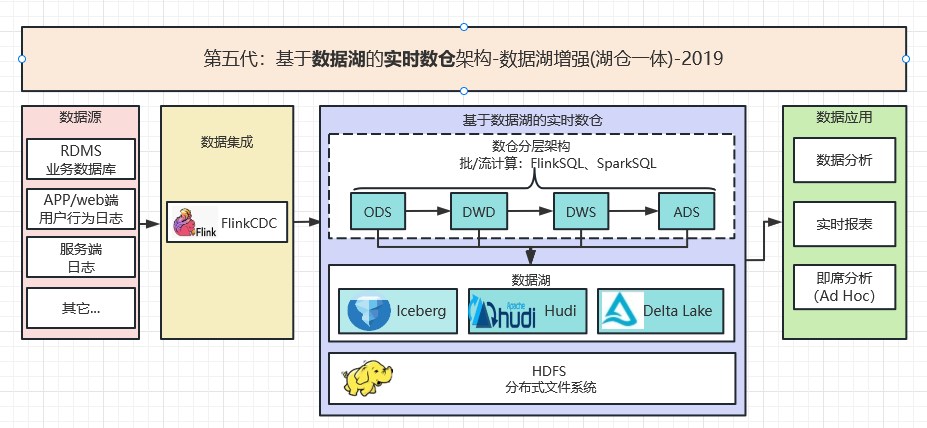
2.5 第五代:基于数据湖的实时数仓架构-数据湖增强(湖仓一体)-2019
数据湖最早是由Pentaho的创始人兼CTO, 詹姆斯·迪克森(James Dixon),在2010年10月纽约Hadoop World大会上提出来的。但再国内一直到19年三大数据湖开源后,才真正火起来。其中又以Flink+Iceberg应用范围最广。该架构的特点如下:
- 支持ACID、schema变更。高效 Table Schema 的变更,比如针对增减分区,增减字段等功能.
- 统一存储的准实时数仓。湖仓一体:数据统一存储在数据湖中(Iceberg、hudi、Delta Lake)。批流一体:同时支持流批读写,不会出现脏读等现象.
- 支持高效upset。
架构如下图所示:
4.展望未来
数据仓库从传统数仓阶段–>大数据数据仓库(数据湖)阶段–>新一代实时数仓(湖仓一体)阶段,整体发展趋势可总结几点:
1.湖仓一体: 数据湖和数据仓库的边界正在慢慢模糊,数据湖自身的治理能力、数据仓库延伸到外部存储的能力都在加强。湖仓一体已成为主流趋势,只是时间而已。中小企业可借助云平台快速实现,例如阿里云MaxCompute。
2.更简单的运维: 技术栈合并,一站式解决方案越来越火。例如Flink+Doris的批流一体OLAP架构(甚至Doris自己都可以)。摒弃大数据入门要学习数不清的工具+技术栈的尴尬境地。
3.新架构/新思想:尚未成熟,不建议接入,了解即可。
- Data Fabric: 元数据驱动基于中心化,基于知识图谱的数据资产管理(元数据驱动)。
- Data Mesh数据网格: 采用DDD领域驱动设计思想。数据治理拆分到各业务领域(类似微服务的服务拆分),分而治之,分别产出业务领域的数据产品。
相关阅读:

2条评论
Pingback:
Pingback: